Article
把 Orca 的 DeepSeek 缓存命中率打到 99%,我做了九轮优化
前言
这几天我在 Orca 里做了一轮比较硬的优化:DeepSeek 上下文缓存。
这件事一开始看起来很简单:既然 DeepSeek 有 prefix cache,那就让每轮请求前缀尽量稳定。系统提示词别乱变,工具 schema 别乱变,对话历史 append-only,不要动老消息。
道理都对。
但真正做下来,我最大的感受是:缓存优化不是靠读代码“想明白”的,它必须拿真实 API 一轮一轮去撞。
因为这里面有太多看起来合理、实际没效果的判断:
- 你以为改了,其实没改到真实 wire prompt。
- 你以为只是本地 token 预算问题,实际 API 请求里还注入了 summary、tools、volatile overlay。
- 你以为 remote summary 可以靠稳定 prompt 命中缓存,真实 API 返回还是 0%。
- 你以为压缩是在省 token,结果一不小心变成压缩风暴,每轮都压。
这篇文章不是一个“胜利总结”。更准确地说,它是一次工程排雷记录。
Orca 最终在真实 API 评测里,压缩后的主链路能稳定到 99% 左右缓存命中。但这个结果不是线性推进出来的,中间有几轮其实是误判,我后来也重新认了账。
背景:Agent 为什么特别吃缓存
普通聊天应用里,缓存命中当然也有价值,但 Agent 对它更敏感。
因为 Agent 不是一问一答。一个稍微复杂点的任务,链路通常是:
用户任务
-> 模型规划
-> 工具调用
-> 工具结果回灌
-> 模型继续推理
-> 再调用工具
-> 再回灌
-> ...每一轮都会把历史上下文再发一遍。
如果 prefix cache 命中,旧历史的成本和延迟都会下降;如果 miss,Agent loop 跑得越久,浪费越大。
所以缓存优化的目标不是“某一轮少几个 token”,而是让多轮循环里的历史前缀尽可能稳定。真正影响成本的,不是第一轮,而是第十轮、第二十轮、压缩之后的下一轮。
先把评测口径说清楚
这次优化里,有一个口径问题非常重要。
Orca 的 usage.updated 事件只统计主链路里的 streaming 模型调用,不统计 compaction summary 那次非流式 API 调用。也就是说,如果只看 Orca 自己吐出来的 usage,压缩路径里最贵、最不命中的那条 summary 调用会被漏掉。
所以做基线时,我用本地 DeepSeek proxy 记录原始 response usage,再用 prompt_cache_hit_tokens / prompt_tokens 算缓存率。
最有代表性的基线样本是一个“完成且触发压缩”的任务:读 tests/workflow_script_contract.rs,触发 tool loop,然后发生 context.collapsed + context.summary。
原始 API 调用缓存率是这样:
| 调用 | 类型 | prompt tokens | cached | 缓存率 |
|---|---|---|---|---|
| 1 | 正常首轮 | 4390 | 2432 | 55.40% |
| 2 | tool result 后 | 6591 | 2432 | 36.90% |
| 3 | compaction summary | 2273 | 0 | 0.00% |
| 4 | summary 后继续 | 6748 | 2432 | 36.04% |
| 5 | 后续稳定轮 | 6871 | 6784 | 98.73% |
总计包含 summary 调用:14080 / 26873 = 52.39%。
如果只看 Orca usage.updated 可见的 streaming 调用:14080 / 24600 = 57.24%。
这两个数字差得不算离谱,但方向很关键:一旦进入压缩路径,summary 调用会把真实总缓存率往下拉。
我还跑过一个更重的压力样本,放大 tool output 到 20k tokens 后,模型没有按 prompt 收束,最后跑成 23 个 streaming 调用 + 12 个 summary 调用,我中止了。这个样本不适合作为“成功任务”的结论,但很能说明风险:
全部 API 调用:86272 / 182312 = 47.32%
仅 streaming 模型调用:86272 / 169586 = 50.87%
summary 调用:0 / 12726 = 0%
history 里记录了 19 次 context.collapsed,其中 12 次有 context.summary所以后面所有优化,不能只问“普通 turn 是否命中”,还要问:
- 压缩路径是否触发?
- summary 调用算进来了没有?
- 压缩后下一轮能不能恢复高命中?
- 会不会进入 compaction storm?
第一处真正的问题:动态信息写进了 system
最早我盯上的问题是 budget hint。
Orca 当时会把剩余上下文预算提示 append 到 system message 的末尾,大概像这样:
<system prompt 静态正文>
[Context budget: ... remaining tokens ...]这里有一个我一开始说错的点:它不是插在第一条 message 的开头,而是追加到 system message 的末尾。
但这并不改变结论,反而更说明问题。
DeepSeek 的 prefix cache 看的是请求前缀。system message 是整段请求最前面的部分。只要 budget hint 每轮变化,system message 从 hint 位置开始就不一样了,后面整段多轮历史也跟着 miss。
这是真正的大头。
不是“一个小提示本身浪费了多少 token”,而是它把后面所有历史的缓存资格都弄没了。
所以第一轮真正的优化很明确:不要把 volatile 信息放进 system prompt。
这一步是实打实的生产代码优化。
后来我看了 Reasonix 的架构文档,它的原则更激进:immutable prefix 一旦建立就不要动,append-only log 只能追加,volatile scratch 不进入缓存前缀。这个思路和我们后面一路撞出来的结论基本一致。
九轮优化:不是一条直线
这里我先把九轮摊开说。因为如果只写最后结果,会把过程写得太顺,反而不真实。
| 轮次 | 当时做的事 | 后来怎么看 |
|---|---|---|
| 第 1 轮 | 去掉 system 里的动态 budget hint,改成本地展示 context usage | 真优化,压缩/多轮样本从约 50% 拉到约 75% |
| 第 2 轮 | 把 plan/skill/goal 这类 volatile 信息从历史 message 中剥离 | 普通 agent loop 有效,非压缩样本到 92.18%;但压缩样本仍被 summary 0% 命中拉垮 |
| 第 3 轮 | Rolling Summary:remote summary 只吃 previous summary + 新 delta,不再吃全量 collapsed 历史 | 有效,summary 请求明显变小 |
| 第 4 轮 | SummaryState:baseline + deltas,渲染成 append-only summary 区 | 部分有效,但真实 resume 暴露“summary + 原文重复”问题 |
| 第 5 轮 | Local Extractive Compaction:remote summary 前先对中等 tool output 做确定性 head/tail 摘要 | 有效但范围比预想窄,超大输出被 micro compact 先处理了 |
| 第 6 轮 | Summary Hash Cache:对 previous summary + delta 做内容寻址,本地命中则跳过 remote summary | 有效,重复同一段 summary 第二次不打 API |
| 第 7 轮 | 单一 deterministic summary renderer + telemetry,试图统一 micro/extractive 两条路径 | 方向对,但第一版策略太保守,真实 API 下 huge 场景反而更贵 |
| 第 8 轮 | 收紧 summary renderer:每工具硬字节预算,更激进 tier;同时优化 pipe-eval-stdin 做真实碰撞 | renderer 达标,但真实碰撞又打出 compaction storm 和 stdin framing 问题 |
| 第 9 轮 | wire-equivalent compaction 判断、60% hysteresis、user/stdin extractive render、resume 持久化 inherited summary_state | 真正把压缩风暴和 summary_state 漂移压住,最后主链路稳定下来 |
这里面最重要的教训是:不是每一轮“看起来合理”的改动都会在真实 API 上变好。
第 7 轮就是一个典型例子。它解决了结构问题:summary renderer 不再被 micro compaction 遮蔽,也有了完整 telemetry。但真实 API 一测,huge 场景比旧路径更贵。因为旧路径虽然“不优雅”,但 micro compact 已经把输入压得很短;新 renderer 从原始内容渲染,证据保留更多,成本也上去了。
所以第 8 轮不是继续讲架构,而是加硬预算:medium 最多约 900 bytes,huge 最多约 700 bytes,行/字符提取之后再做字符边界安全裁剪。真实 API 下:
summary_huge_old_micro_masked prompt=235
summary_huge_current_original_renderer prompt=235
summary_mid_old_without_renderer prompt=2100
summary_mid_current_renderer prompt=307
normal_turn_2 hit=99.2%这才算把第 7 轮的方向补成了可落地的优化。
第二处问题:动态状态不能混进历史消息
budget hint 之后,另一个问题藏在会话结构里。
Orca 有一些运行时状态,比如:
- 当前 plan
- 当前 goal
- skill context
这些东西对模型有用,但它们会变化。
早期做法是把它们作为特殊 message 放进 conversation.messages,更新时先删除旧块,再 push 新块。
问题就在这里。
假设某一轮历史是:
system
history A
plan_v1
user N
assistant N
tool result N下一次 plan 更新后,如果把 plan_v1 从中间删掉,再把 plan_v2 push 到末尾,就会变成:
system
history A
user N
assistant N
tool result N
plan_v2从 plan_v1 原来的位置开始,wire prompt 已经完全不一样了。
这不是“plan 自己 miss 一点”的问题,而是它后面的整段历史都被重新排列了。
最后的处理是:这些动态状态不再作为历史 message 的一部分保存。
它们进入 volatile state,在真正发请求时,渲染成一个 overlay,挂到当前轮尾部。这样旧历史保持 append-only,动态状态只影响靠后的部分。
这轮真实评测里,普通 agent loop 覆盖了 update_plan + read Cargo.toml,没有触发 summary:
calls: 3
prompt_tokens: 14,441
cache_hit: 13,312
cache_miss: 1,129
hit_rate: 92.18%但压缩样本仍然很差:
summary call: prompt=18,980 hit=0 hit_rate=0%
main call after summary: prompt=4,478 hit=2,432 hit_rate=54.31%
total including summary: prompt=23,458 hit=2,432 hit_rate=10.37%这说明第二轮方向是对的,但它只解决普通 turn 的历史污染。只要进入 remote summary,真实总缓存率还是会被 0% 命中的 summary 调用拉垮。
这一步让我重新确认了一件事:conversation 的内存结构不是缓存真相,发给模型的 wire prompt 才是缓存真相。
你可以在内存里怎么组织都行,但只要最终 wire 顺序动了,缓存就会碎。
第三处问题:本地 token 预算不等于真实请求预算
后面评测时又撞到一个问题:明明本地估算没有超上下文,真实 API 调用却还是触发压缩,甚至出现压缩后马上又压缩的情况。
原因是本地预算一开始算得不够“像真实请求”。
真实发给 DeepSeek 的不只是 conversation.messages,还包括:
- system prompt
- injected summary messages
- volatile overlay
- tools schema
- message 包装开销
如果本地只数 conversation messages,就会低估请求体。
低估的结果很糟糕:系统以为“不需要压缩”,但真实请求已经接近上限;或者压缩后以为“已经安全”,下一轮又被真实 wire prompt 打爆,于是继续压缩。
这就是压缩风暴。
第 8 轮真实碰撞把这个问题打得很明显。低阈值触发 compaction 后,后续几轮是这样:
turn2-resume-compact input=20713 cache=12416 hit=59.9%
turn3-after-compact input=20787 cache=2432 hit=11.7%
turn4-continue input=20881 cache=2432 hit=11.6%
turn5-continue input=20998 cache=2432 hit=11.6%同时 remote summary 每轮都是 miss:
orca.remote_summary requested=1 purpose=delta cache_hit=0 cache_miss=1这组数据的关键不是“某一轮命中率低”,而是:压缩后仍然发出 20k+ input,超过我设置的 auto_compact_token_limit=18000。也就是说,本地以为压完了,真实 wire prompt 仍然超阈值,于是下一轮继续压。
这就是 compaction storm。
所以后面加了 needs_compaction_wire 这类 wire 等价判断:按真实请求形态估 token,而不是按内存结构估 token。
这一步不是为了追求 token 计算绝对精准,而是为了让本地判断和真实 API 行为同向。
Agent 系统里这种差一点的估算很危险。因为它不是单次误差,而是会进入 loop,变成持续错误。
第 9 轮还加了一个很重要的东西:hysteresis。压缩不能只压到“刚好低于阈值”,否则一两条新消息又把它顶回去。后面改成压到目标窗口的 60% 左右,让压缩后留出足够缓冲。
第四处问题:压缩不是删历史,而是维护协议
一开始说“上下文压缩”,很容易想到把旧消息总结一下,然后替换掉。
但对 prefix cache 来说,压缩不是简单的“减少 token”。它其实是在改变后续所有请求的前缀结构。
如果每次压缩都重写历史、重排消息、让 summary 位置漂移,那缓存还是会碎。
后面 Orca 改成了更明确的 summary state:
- baseline summary:长期稳定的摘要基线
- delta summaries:后续压缩产生的增量摘要
- kept messages:最近需要保留的原始消息
这样压缩之后的请求结构更像:
system
summary baseline
summary delta 1
summary delta 2
kept recent messages
current turn压缩不再是“随手把历史改短”,而是维护一个可恢复、可持久化、可继续追加的 summary 状态。
这里还修了一个很现实的问题:resume / continue 后必须把继承来的 summary state 写回新 transcript。
否则这次进程里看起来 summary 还在,下一次从历史恢复时 summary shape 丢了,又会重新触发压缩。缓存问题就会从“上下文策略问题”变成“会话持久化问题”。
第三轮和第四轮一起评测时,暴露过一个很典型的问题。
当时 C 场景里第二次压缩后,主请求确实渲染成了:
[Summary baseline]
[Summary update 1]
kept tail
current userhistory 里也写出了 summary_state:baseline 长度 620,delta 数量 1,delta 长度 392。
但 D 场景 resume 后继续请求时,虽然恢复了 baseline + delta,原始被压缩的大段历史也从 history message log 里回来了。也就是说,请求里出现了“summary + 原文重复”。
这件事提醒我:summary_state 持久化对了,不代表 resume 语义就对了。
压缩不是只在当前进程里成立,它必须跨 transcript、跨 --continue、跨 TUI resume 都成立。否则长期任务会把已经压缩过的原文再带回来,既拖垮上下文窗口,也拖垮缓存前缀。
最麻烦的一条支路:remote summary
主链路逐渐稳定之后,remote summary 成了新的问题。
所谓 remote summary,就是把要折叠的历史片段交给模型总结。这个动作本身也是一次 API 调用,也有 input tokens,也可能命中缓存。
我一开始的直觉是:那就让 summary prompt 也稳定一点,争取它也命中缓存。
真实 API 给了很直接的反馈:没用。
优化前,remote summary telemetry 是这样:
orca.remote_summary_usage purpose=delta input_tokens=257 output_tokens=192 cache_tokens=0 cache_hit_ratio=0.0000
orca.remote_summary_usage purpose=delta input_tokens=581 output_tokens=422 cache_tokens=0 cache_hit_ratio=0.0000后来尝试把 summary system prompt 做得更长、更稳定,结果是:
orca.remote_summary_usage purpose=delta input_tokens=462 output_tokens=211 cache_tokens=0 cache_hit_ratio=0.0000
orca.remote_summary_usage purpose=delta input_tokens=849 output_tokens=471 cache_tokens=0 cache_hit_ratio=0.0000token 更多了,命中还是 0。
这就是典型的“看起来像优化,真实 API 不认”。
所以最后的方案不是继续调 remote summary prompt,而是换一个问题问法:
有没有必要每次都 remote summary?
答案是:不一定。
这条路中间经历了几次拆分。
第一步是 Rolling Summary。以前 remote summary 更像是“把当前要折叠的历史重新总结一遍”,后来改成只喂 previous summary + 新折叠 delta。这样第一次 summary 可能还大,但第二次以后只处理新增片段。真实评测里,第一次 summary call 是 16,272 prompt tokens;第二次已有 baseline 后降到 11,764,而且没有把 previous summary 再塞进去。
第二步是 SummaryState。把 summary 拆成 baseline + deltas 后,主上下文里的 summary 区域可以 append-only。baseline 稳定,delta 追加,只有 delta 太多或太长时才低频 rebuild baseline。
第三步是 Local Extractive Compaction + Summary Hash Cache。
Local Extractive Compaction 先对 collapsed delta 里的 tool output 做确定性压缩:大输出保留 head/tail 和尺寸标记,自然语言对话原样保留。这样 remote summary 看到的 delta 更小,而且同一段输入渲染出来永远一样。
Summary Hash Cache 则对 previous_summary + delta_text 做内容寻址。第一次 miss 才打 remote summary,第二次同输入直接从本地 cache 读。
这轮验证里,我第一次让 compact_with_summary(DeepSeek) 真打远程 summary,然后把 cache 文件内容改成 sentinel,第二次同输入返回了 sentinel:
first_kind=remote
second_kind=remote
cache_files_after_first=1
cache_files_after_second=1
second_summary=SENTINEL_REAL_API_CACHE这说明产品代码里本地 summary cache 确实能跳过重复远程 summary。
对于中等大小的 delta,我们可以做确定性的 extractive summary delta:
- 保留消息角色和关键边界
- 大块 stdin / tool output / assistant content 做 head-tail 提取
- 记录 omitted bytes / chars 等元信息
- 去掉 assistant reasoning content
- 输出稳定、可测试、可缓存
这不是让本地 summary 取代模型理解一切。它只是处理一类很常见的场景:旧内容太长,但并不需要模型重新“理解成文学摘要”,只需要把证据压到一个稳定、可继续携带的形态。
这里还有一个弯路。
第 7 轮我把 renderer 统一成单入口后,离线 harness 很好看:mid-sized tool output 有 76% token 降幅,huge output 有 96.3% 降幅。但真实 API 评测发现,它相对“原始 huge output”是省了,可相对旧的 micro-compacted 路径反而更贵。
当时真实 API 是这样:
summary_mid_old_without_renderer prompt=3932
summary_mid_current_renderer prompt=3848
summary_huge_old_micro_masked prompt=2252
summary_huge_current_original_renderer prompt=5644所以第 8 轮才加了硬预算。目标不是“相对原文省”,而是“不能输给旧路径”。这点很重要,优化不能只找一个更容易赢的参照物。
第九轮之后,最终评测里 remote summary telemetry 为空。
也就是说,那两次中等 delta 压缩没有再调用 remote summary。
这个结果比“remote summary 命中缓存”更好:直接没有这次调用。
最终真实 API 评测
最后一轮评测不是 mock,也不是只跑单轮。它用真实 DeepSeek API,构造了三段较大的输入,通过 stdin 喂给 Orca,并且强制进入压缩场景。
这组结果读的时候也要注意口径:它来自第九轮后的 pipe-eval-stdin 多进程 --continue 场景,主调用读 Orca 的 usage.updated;同时开了 ORCA_SUMMARY_DEBUG 看 remote summary telemetry。最终 telemetry 为空,说明这组中等 delta 压缩没有再产生 remote summary 调用,所以这里不存在“summary 调用被 usage.updated 漏算”的问题。
评测流程大概是:
turn1: 注入 alpha 大块数据
turn2: 注入 beta 大块数据,触发第一次压缩
turn3: 压缩后继续对话
turn4: 稳定性检查
turn5: 注入 gamma 大块数据,触发第二次压缩
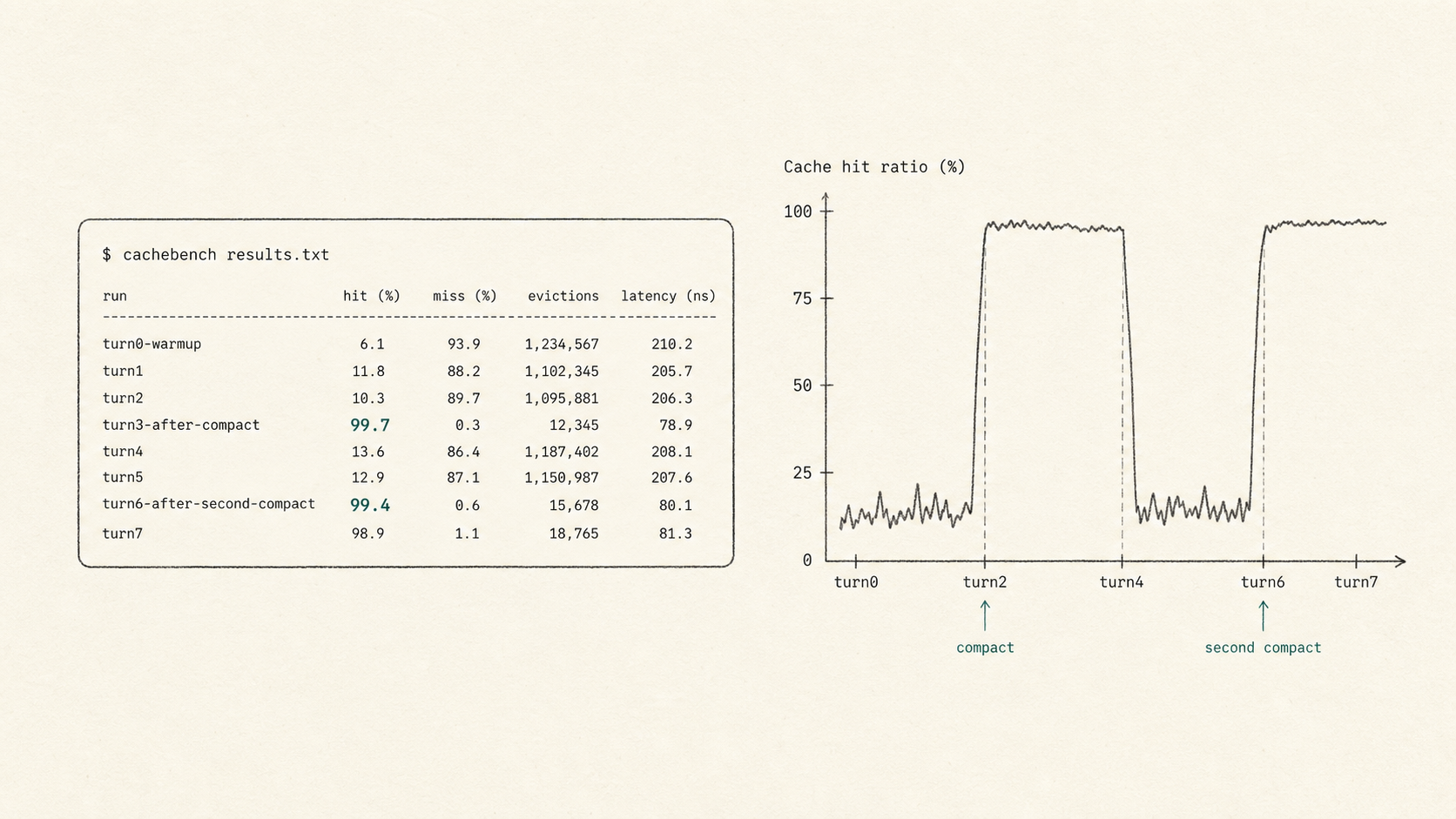
turn6: 第二次压缩后继续对话最后一次有效评测结果:
| 回合 | input tokens | cache tokens | 命中率 | 说明 |
|---|---|---|---|---|
| turn1-seed | 18398 | 0 | 0.0% | 冷启动,预期为 0 |
| turn2-trigger-compact | 18585 | 0 | 0.0% | 新增大块输入并触发首次压缩,预期较低 |
| turn3-after-compact | 18612 | 18560 | 99.7% | 第一次压缩后,主链路基本全命中 |
| turn4-stability | 18687 | 18560 | 99.3% | 稳定续跑,命中保持 |
| turn5-trigger-second-compact | 18906 | 2432 | 12.9% | 第二次注入大块输入并触发压缩,只有较短稳定前缀命中 |
| turn6-after-second-compact | 18933 | 18816 | 99.4% | 第二次压缩后,主链路再次恢复高命中 |
原始输出里是这样:
turn1-seed input=18398 cache=0 hit=0.0%
turn2-trigger-compact input=18585 cache=0 hit=0.0%
turn3-after-compact input=18612 cache=18560 hit=99.7%
turn4-stability input=18687 cache=18560 hit=99.3%
turn5-trigger-second-compact input=18906 cache=2432 hit=12.9%
turn6-after-second-compact input=18933 cache=18816 hit=99.4%这里不要误读 turn2 和 turn5。
它们是主动注入新大块数据、触发压缩的回合,本来就不是最适合命中的回合。真正要看的是压缩之后的下一轮:turn3 和 turn6。
这两个回合都到了 99% 左右。
这说明压缩后的新上下文结构稳定了,后续主链路不再因为 summary、volatile 状态、预算 hint 或历史重排而整体 miss。
这组数据还有一个隐含结论:真正稳定的不是“永远 99%”。触发压缩、注入新大块数据的那一轮,命中率本来就会低。关键是压缩后的下一轮能不能恢复。如果恢复不了,就说明 summary 区、tail、volatile overlay 或预算判断仍然在扰动前缀。
这次优化真正得到的原则
如果把这九轮收敛成几条原则,我会这么写。
1. system prompt 只能放真正不变的东西
system prompt 是缓存前缀的地基。
剩余预算、当前 plan、临时状态、动态提示,不管看起来多小,都不应该写进去。
小的动态文本会破坏大的历史缓存。
2. append-only 比“整理得更干净”重要
对话历史不要为了看起来整齐而重排。
删掉中间一块再 push 到末尾,在数据结构里可能很自然,但在 prefix cache 眼里就是灾难。
Agent 的 conversation log 应该更像事件流:旧内容一旦进入历史,就尽量不要原地变形。
3. 本地结构不重要,wire prompt 才重要
缓存命中看的是发给模型的字节序列,不是你内存里的抽象对象。
所以预算、测试、snapshot 都要尽量对齐 wire prompt。
这也是为什么后面要把 summary messages、volatile overlay、tools schema 都算进预算里。
4. 压缩是协议,不是字符串处理
压缩后的上下文形态必须稳定、可恢复、可持久化。
如果压缩只是“这次临时把历史截一下”,那 resume、continue、第二次 compact 都会把问题重新引出来。
summary state 其实就是一份协议:旧历史如何被代表,新 delta 如何追加,什么时候需要重建 baseline。
5. 不要执着于优化一条不值得优化的调用
remote summary 一直 0% cache 命中时,最容易犯的错是继续调 prompt。
但真实评测已经说明这条路不划算。
最后真正有效的是减少 remote summary 发生的次数:中等 delta 本地确定性渲染,巨大 delta 才交给模型。
有时候最好的缓存优化,是让那次请求根本不要发生。
6. 真实 API 是唯一裁判
这次最重要的变化不是某个函数,而是评测方式。
后来我专门做了 pipe-eval-stdin,让真实碰撞变简单:可以把大块输入直接 pipe 给 orca exec,再用脚本连续跑 resume / compact / stability 场景。
这让优化从“我觉得应该会命中”变成了:
你说得对,但 cache_tokens 是多少?这句话很朴素,但救了很多时间。
这里还有一个细节:stdin 评测也必须 byte-stable。
第 8 轮做过一个单变量实验:
A-repeat-base-2 input=12521 cache=12416 hit=99.2%
B-tail-diff input=12521 cache=12416 hit=99.2%
C-head-diff input=12494 cache=4224 hit=33.8%
D-prompt-diff input=12526 cache=4224 hit=33.7%
E-full-stdin input=12515 cache=4224 hit=33.8%尾部变化很安全;只要 user/prompt/stdin framing 的前部变了,基本只剩 system + tools 命中。
所以评测工具本身也会影响缓存结论。pipe-eval-stdin 的价值不只是“喂大输入方便”,还在于它能把 prompt 参数和 stdin framing 固定下来,让后续碰撞更像真实、也更可比。
现在能不能先告一段落?
我觉得可以。
不是说缓存这件事已经到终点,而是这条主链路已经从“玄学”变成了“可解释、可复现、可继续优化”的状态。
现在的结论是:
- 普通多轮续跑的历史前缀已经稳定。
- 压缩后的下一轮能回到 99% 左右命中。
- 中等 delta 不再触发 remote summary。
- remote summary 的 0% cache 问题不再是主链路上的持续成本。
- 压缩风暴和 summary state 继承丢失已经被真实场景打过。
后面当然还有可以做的事,比如更细的线上分布统计、更复杂的工具调用场景、更极端的大文件输入、更严格的 wire snapshot 回归测试。但这些已经不是“主链路还没站稳”的问题,而是继续扩大覆盖面的工程工作。
对我来说,这次优化真正改变的不是某个命中率数字,而是 Orca 的开发方法。
以前我会先从代码里推理:这里应该稳定,那里应该 append-only,这样应该命中。
现在我更愿意反过来:
先设计一个真实碰撞场景。
用 API 跑。
拿 cache_tokens 说话。
再回代码里找为什么。
Agent 系统很多问题都是这样。你可以从架构上建立方向感,但最后一定要回到真实调用。因为模型服务、上下文序列化、工具注入、压缩策略、会话恢复,这些东西合在一起之后,行为往往会比单看代码复杂得多。
缓存优化尤其如此。
它不是“少发一点 token”的小修小补,而是一件关于上下文结构、运行时状态、历史协议和真实 API 行为的系统工程。
但缓存也只是 Agent 优化里的一个点。
它解决的是“同样的上下文,能不能更稳定、更便宜、更快地被模型复用”。这很重要,尤其对长任务和高频 Agent loop 来说,缓存命中率就是成本、延迟和可持续性的地基。
可 Agent 的最终效果不只由缓存决定。缓存打稳之后,后面还有更长的路:工具调用是否准确,压缩后的 summary 是否真的保留了关键事实,多轮计划会不会漂移,目标状态能不能正确继承,验证器、测试、diff、审批这些 harness 能不能把“看起来完成”变成“可信完成”。
很多效果问题不像缓存这么诚实,它不会给你一个清清楚楚的 hit rate。它可能表现成工具选错、总结漏事实、计划走偏、测试没覆盖、失败语义不清。那些问题同样需要真实任务去碰撞,只是 metric 会更难设计。
所以这轮缓存优化可以先告一段落,但 Orca 的效果优化远没结束。
这九轮做完,我对这件事的判断反而更简单了:
最大强度的缓存优化,不是不断猜哪里能省,而是不断拿真实调用去碰撞,直到系统暴露出它真正的边界。
而最大强度的 Agent 优化,也差不多是同一件事:不断拿真实任务去碰撞,把“我觉得它会做得更好”变成可观察、可复现、可回归的数据。
这大概是这次优化最值钱的收获。不是某个聪明的改动,而是一套能让假设变成数据的工作流。
Keep Reading