Article
DeepSeek DSpark:重点不是新模型,而是推理系统能力
DSpark 这件事,我不太想把它写成“DeepSeek 又发了一个更强的新模型”。
更准确地说,它是 DeepSeek 把推理加速这件事,从算法 demo 往生产系统里又推进了一步。
很多人看这类消息,第一反应会盯着“速度提升 60% 到 85%”“吞吐提升 661%”这些数字。
但我觉得真正值得看的不是这个。
DSpark 最有意思的地方在于,它没有只问一个问题:
怎么让模型一次多吐几个 token?
它问的是另一个更工程化的问题:
在高并发服务里,哪些 token 值得让主模型花钱验证,哪些 token 应该提前放弃?
这个问题一变,味道就不一样了。
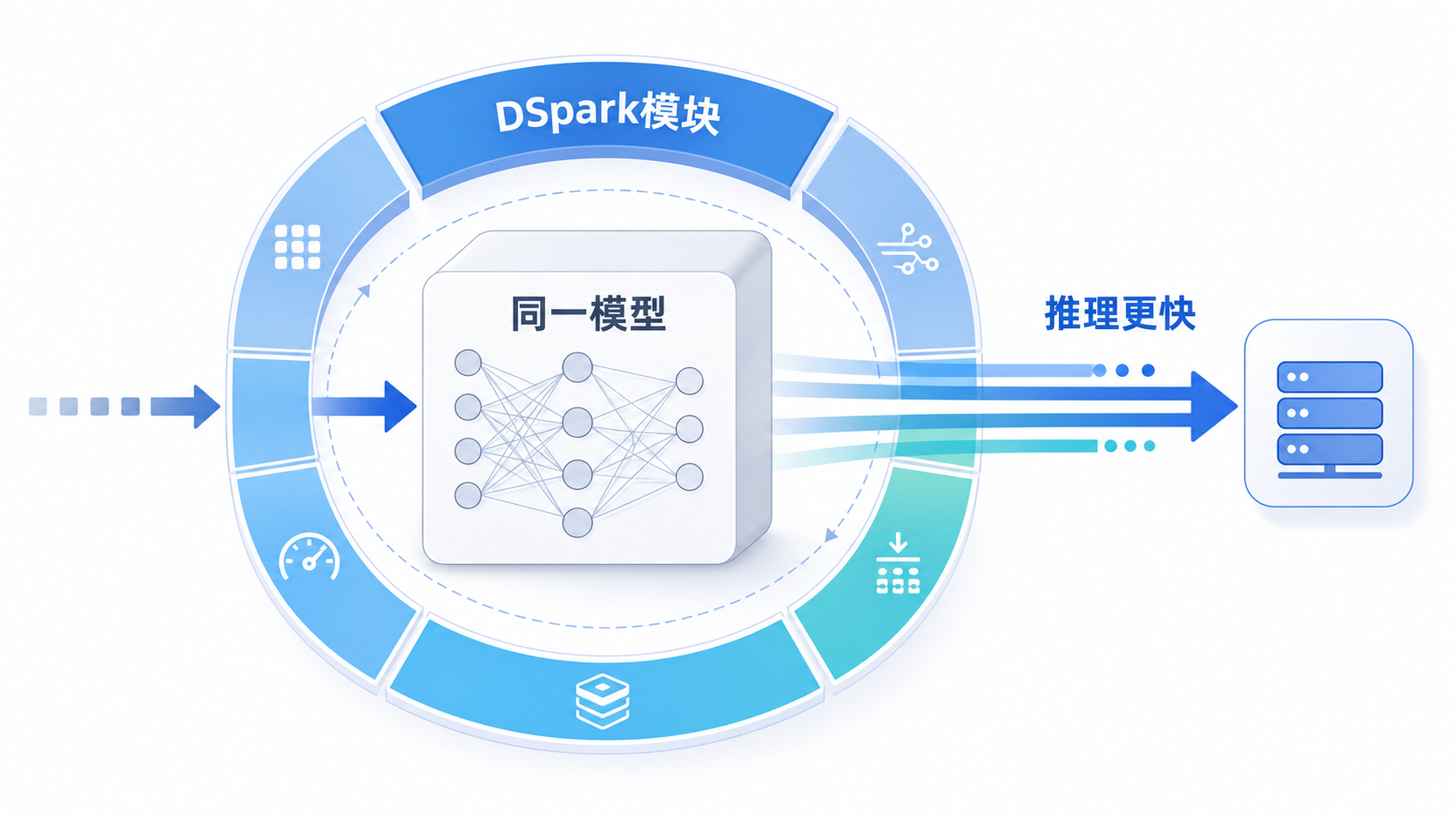
DSpark 更接近推理服务层的加速模块,不是一个新的基础模型。
推测解码的麻烦,不是“猜”,而是“验”
大模型生成文本,本质上还是自回归:一个 token 一个 token 往外吐。每生成一个新 token,都要走一次模型前向。用户看到的是“它怎么还没说完”,服务侧看到的是 GPU 一轮一轮被占住。
推测解码就是为了解这个问题。
简单说,让一个小一点、便宜一点的草稿模型先猜一段,再让大模型一次性验证。如果猜对了,就相当于一轮前向推进了多个 token;如果猜错了,就回退到大模型本身的分布。
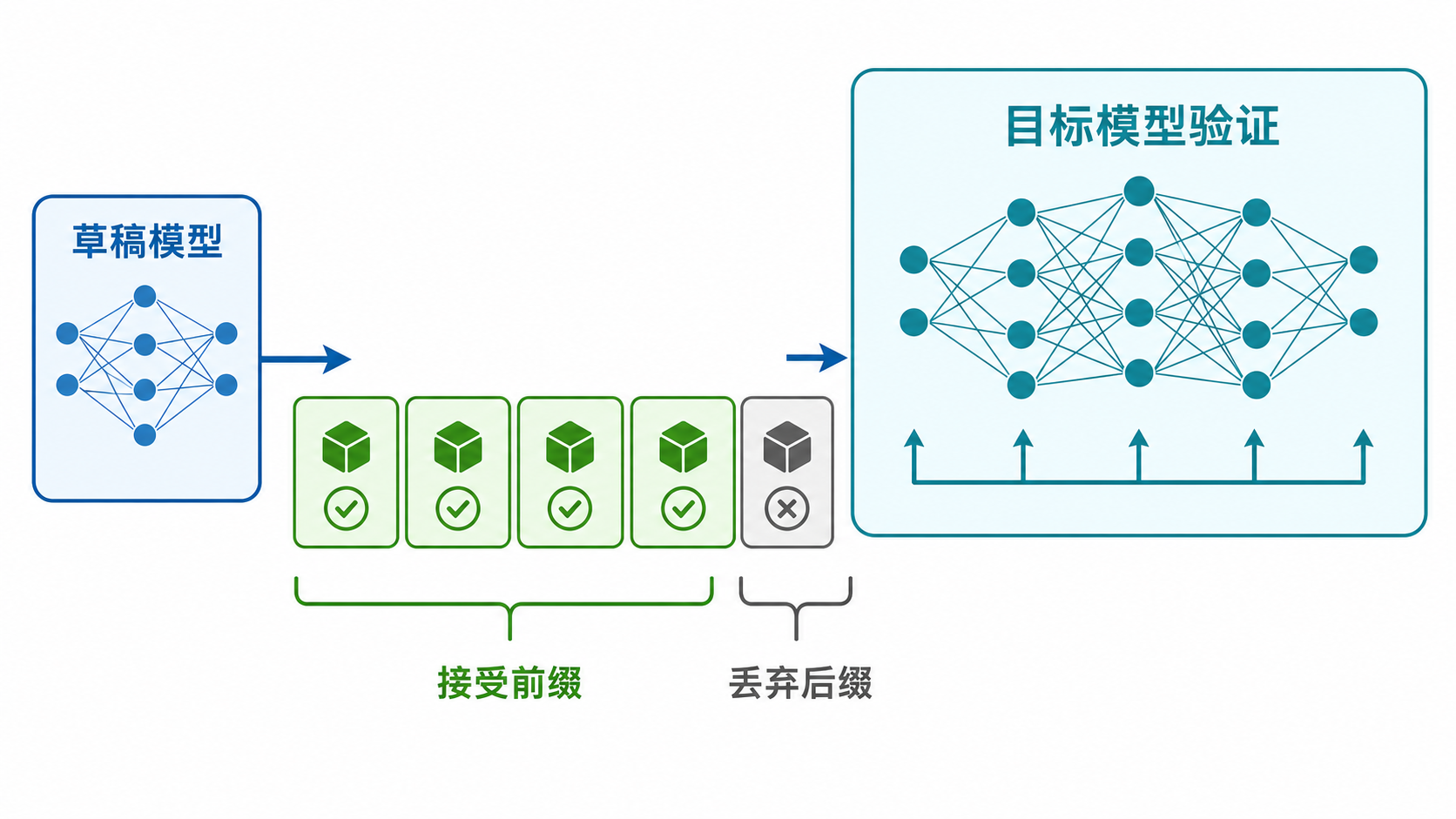
推测解码的关键不是“猜更多”,而是猜出来以后能不能被目标模型连续接受。
这套思路本身不新。
真正难的是:生产环境里,草稿模型猜错的部分不是免费的。
你让草稿模型多猜几个 token,看上去很美。但这些 token 最后都要拿去给目标模型验证。低并发时还好,GPU 反正有空,浪费一点也没那么疼。高并发时就完全不一样了,每一个大概率会被拒掉的尾部 token,都在占用本来可以服务其他用户的 batch 容量。
所以 DSpark 的核心不是“更激进地猜”,而是“更克制地验证”。
半自回归:给并行草稿补一点顺序依赖
DSpark 主要做了两件事。
一个是半自回归的草稿生成。
以前大概有两条路。
自回归草稿模型,比如 Eagle3,一步一步生成候选 token。好处是后面的 token 能依赖前面已经采样出来的 token,所以语义更连贯、接受率更稳。坏处也很明显:你草稿模型自己也开始一个 token 一个 token 跑,候选块一长,延迟就上来了。
并行草稿模型,比如 DFlash,一次前向把一整段候选 token 都吐出来。这个方向延迟漂亮,但问题是每个位置在生成时看不到块内前面已经采样出来的 token。前几个 token 可能还行,越往后越容易出现语义路径冲突,后缀接受率掉得很快。
DSpark 的做法是折中:先用一个并行主干一次性产出所有候选位置的隐藏状态和基础 logits,再用一个很轻的顺序模块,把前缀依赖补进去。
论文里有个细节挺说明问题:两层 Transformer 深度的 DSpark,就能在测试领域上超过五层 DFlash 的接受长度。
这其实说明了一件事:有时候不是“再堆一点网络”就能解决问题。并行生成缺的不是单纯容量,而是候选 token 之间那点顺序依赖。少量自回归信息,放在正确的位置,性价比比硬堆层数高。
置信度调度:别把主模型算力花在低价值 token 上
另一个,也是我更看重的,是置信度调度验证。
DSpark 会给每个候选位置输出一个置信度,大致可以理解为:在前面的 token 都被接受的前提下,这个 token 还能继续活下来的概率。
然后调度器不是固定验证 3 个、5 个 token,而是结合当前 batch、请求负载和引擎实测吞吐曲线,动态决定每个请求到底验证多长。
这就很生产了。
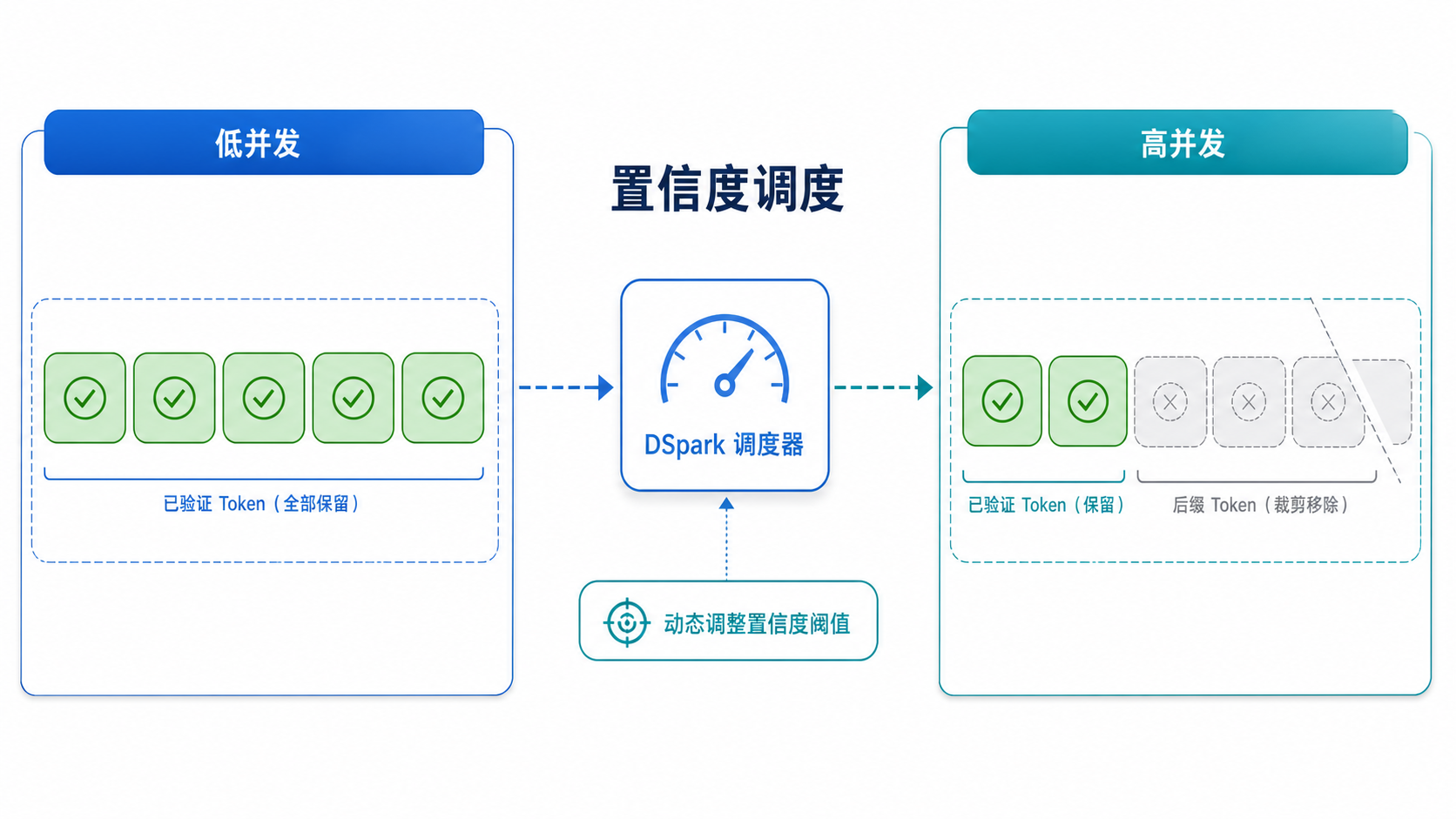
低并发时多验证几个 token,高并发时主动砍掉低置信度后缀,少占目标模型的 batch 容量。
低并发时,它可以多放几个 token 进去验证,因为额外验证的机会成本不高。
高并发时,它会收缩验证长度,把目标模型的计算资源优先给那些全局存活概率更高的 token。
换句话说:
模型负责产生可能性,调度器负责决定哪些可能性值得让主模型花钱验证。
这个判断比“又快了多少”更重要。
因为真实系统里的推理性能,很少只是一个模型结构问题。它同时是调度问题、batch 问题、kernel 问题、SLA 问题、吞吐和延迟的取舍问题。
线上数字要看,但别被大数字带跑
DSpark 在线上数据里确实给了比较漂亮的结果。
在 DeepSeek-V4-Flash 上,匹配实际吞吐水平时,单用户生成速度提升大概 60% 到 85%。在 DeepSeek-V4-Pro 上,是 57% 到 78%。
但这里要小心,不要把 661%、406% 这种数字直接写成“模型快了六倍”。
论文里说得比较克制:在更严格的 SLA 下,比如 Flash 的 120 token/s/user,原来的 MTP-1 单 token 基线已经接近运行边界,只能维持很小的并发 batch,所以 DSpark 的相对吞吐优势会显得特别大。
这个数字真正说明的是:DSpark 把系统在高交互性要求下的可用边界往外推了。
不是简单的“同等条件下暴力快 6 倍”。
我觉得这点反而更值得写。因为它说明 DeepSeek 没有只拿一个好看的 benchmark 数字出来讲故事,而是在讲一个服务系统里的 Pareto frontier:用户侧 token/s 要更高,系统侧 token/s/gpu 也不能塌。
对 Agent 来说,它解决的是很关键的一段
这对 Agent 场景尤其重要。
普通聊天里,快一点当然好。但在 Coding Agent、Browser Agent、复杂工具调用链里,模型不是只回答一句话。它要计划、读文件、调用工具、解释结果、再决策,很多时候一次任务会产生很长的 decode 链。
这时候生成速度不只是体感问题,它会直接影响 agent loop 的周转速度。
当然,也别把 DSpark 神化。
Agent 慢,不只慢在模型吐字。工具调用、上下文组装、检索、沙箱执行、测试等待、网络 IO、长上下文 KV 管理,这些都会成为瓶颈。
DSpark 解决的是推理生成这一段,而且是非常关键的一段,但不是整个 Agent 系统的全部。
还有一个边界也要说清楚:DSpark 是推测解码模块,不是一个新的基础模型。
DeepSeek 在 Hugging Face 的 model card 里也写得很清楚,V4-Pro-DSpark / V4-Flash-DSpark 是在同一个 checkpoint 上附加 speculative decoding module。也就是说,它提升的是服务推理效率,不是模型能力本身突然升级。
另外,DeepSpec 开源当然是好事,里面有 DSpark、DFlash、Eagle3 的训练和评估代码,也有 checkpoint。但这不等于普通团队 clone 一下就能复刻 DeepSeek 的线上效果。
论文里生产部署那部分其实很重:CUDA graph replay、Zero-Overhead Scheduling、异步调度、动态变长验证、把物理执行和逻辑序列跟踪解耦、修改 index-attention 和 compress kernel。
这些才是“能不能上生产”的分水岭。
很多推理加速方案在论文里看起来都不错,一到线上就会被高并发、batch 抖动、kernel 利用率、SLA 和成本打回原形。DSpark 值得关注的地方就在这里:它不是只提出一个草稿模型,而是把草稿生成、置信度校准、硬件感知调度和服务引擎改造连在一起做。
所以我对 DSpark 的评价是:
它不是一次模型能力发布,而是一次推理系统能力发布。
如果只看用户侧,它的价值是回答更快。
如果看工程侧,它的价值是让系统在高并发下少做无效验证,把昂贵的目标模型计算用在更可能被接受的 token 上。
如果看行业趋势,它说明接下来大模型竞争不会只发生在参数、数据和后训练上,也会越来越多发生在 serving 这一层:谁能更好地调度 GPU,谁能更稳定地维持低延迟和高吞吐,谁就能把同样的模型能力用得更便宜、更顺滑。
这大概也是 DSpark 最值得关注的地方。
不是“模型又聪明了”。
而是“系统更会花算力了”。
参考:
Keep Reading